3 min to read
Engineering dishes, logic guidance

The culture of a region and the local delicacies are always inseparable. This applies to small villages or large cities, each would have their unique “taste”.

While traveling foreign countries, restraint menus often have extravagant and misleading titles. This can often lead to dissatisfaction or confusion for the ordered food. So as a tech nerd, is it possible to use machine learning models to predict the taste of dishes through ingredients?
It is actually not hard to implement. As long as the machine learning method can build, train and test the model, the optimized model will be selected through evaluation matrix, and mapping between the materials used and dishes can be realized. To achieve the desired functionality, we need to perform the following three steps.
1. Enter and analyze the data
2. Build the model
3. Model predictionLet’s take Italian dishes as an example. In the following graph, “id” represents different ingredients and “cuisine” is the menu title.
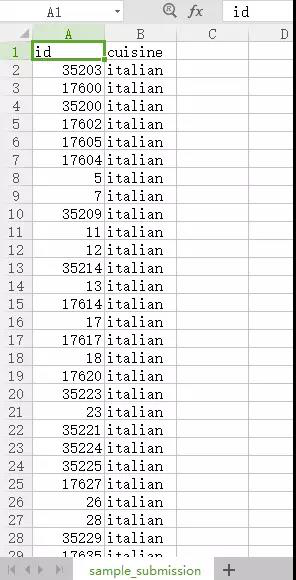
The data is first extracted, and the recipe nodes are as follows. It contains a set of recipes, dish types and ingredient lists.

Features and targets are then assigned to “train_ingredients” and “train_targets” respectively. Through Statistical analysis, we can find the 10 most used ingredients, and add their frequency and name to the “sum_ingredients” dictionary. Through the sample data, the top 10 most frequently used materials in the Italian cuisine can also be calculated, and the material name and the number of occurrences are assigned to the “italian_ingredients” dictionary.
The results can then be visualized by matplotlib. Through data analysis, you can get a lot of interesting information. For example, the most used ingredients in Brazilian cuisine are onions, olive oil, and lemon. In China, lemons are obviously not frequently used in home cooking. The most used ingredients are sauce, sesame oil, corn starch and so on. Soy sauce can be reasonably predicted to have a large correlation to China’s number one material!
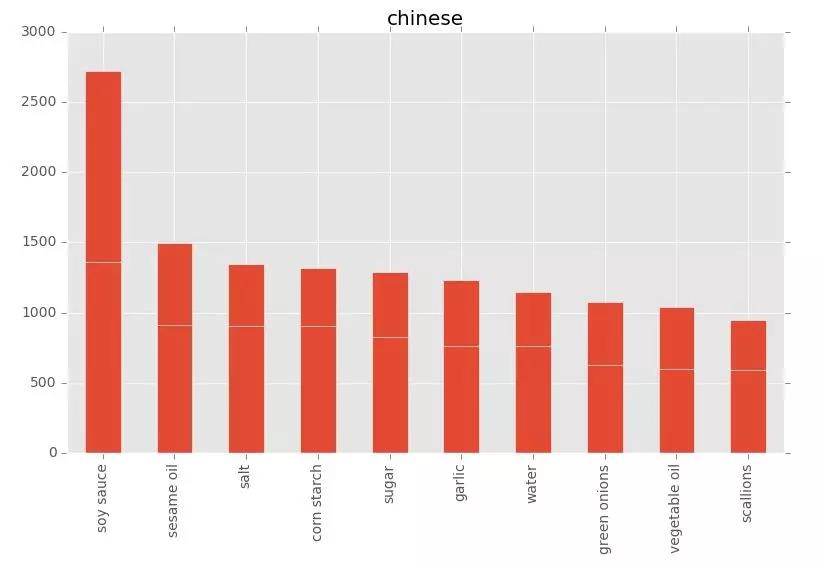
Japan’s delicacies sake and soy sauce are also on the list. In Russia, butter is an essential ingredient and an important source of energy for the ferocious people in the cold weather. So according to our newfound information, if you like butter, potatoes and milk, go to the UK!

Model building is a little more complicated. It mainly follows four steps:
1. Word filtering
2. Trait extraction
3. Data sorting and rearrangement
4. Train the modelIn the process of training the model, you need to try different parameters and pick the model with the best generalization. By training the model, the score on the validation set can be calculated. The higher the score, the higher the classification accuracy (percentage of correctly classified dishes). Once completed, you have a successful model!
In the test file test.json, the format of the recipe is the same as train.json, only the dish type is deleted, because it is the target variable we want to predict.
In conclusion, the process of predicting a cuisine through ingredients is not complicated. What we aim to accomplish is the improvement of code, model optimization, and accuracy of classification and matching. If the data cannot be effectively cleaned and sorted, many French dishes may be misclassified as Italian dishes.


Comments